


This AI design and application blog series is authored by Revcast's head of product, Alex Gibson.
AI Agents have become unavoidable. They’ve graduated from cutting-edge novelty to baseline table stakes, to the point where you’d swear there’s a coven of magical AI Agents lurking through your offices right now. For every CEO-demanded integrated chatbot and thought-provoking Twitter thread, there’s just as much useless noise and even some actual fraud.
However, there’s comparatively less information about what really goes into an “AI Agent.” Are they chat interfaces with access to API keys? Magical black-boxes that write code so well you’ll soon fire all those expensive Software Engineers? Marketing hype with a splash of shiny CSS gradients?
This content is about our experience at Revcast planning, building, and maintaining genuine AI Agents in our production SaaS.
Genuine AI Agents are learning-driven software entities that converse in natural language and wield agency to autonomously select the right tools and data to achieve an objective. They have fundamentally changed the expectations that people have around enterprise software. Achieving genuine AI Agent functionality requires less new wave mysticism and vibe coding and more old-school rigorous design, disciplined data modeling, and thoughtful plan execution. Or, as Jason Lemkin reminded us recently: “Building Great Software is Still Hard”. Let’s dive in.
Focus on What You Can Control
You can’t wrestle an LLM into behaving perfectly. Models shift, endpoints throttle, and what worked last week might not tomorrow. Such is life with nondeterminism regulated by large service providers. Simply throwing things at a model is a recipe for garbage. Your true levers lie not in some black-box magic of an LLM, but in the software you own: the data you feed the model, the context you craft, the tools you expose (and don’t expose), and the prompts you test.
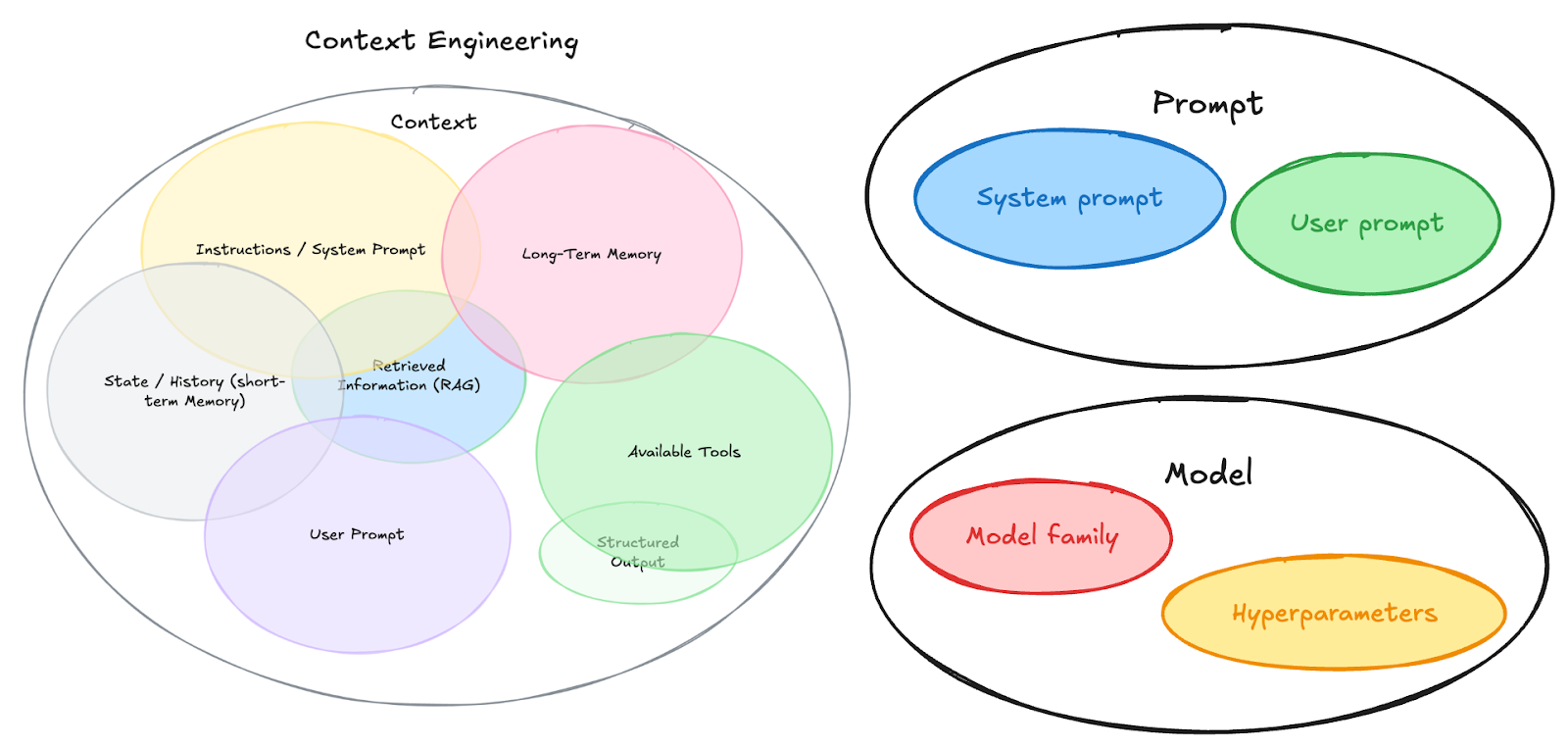
Image above: Pieces of the AI Agent puzzle. “Context Engineering” - copied from Phil Schmid’s excellent writeup, appended to encompass the fuller picture.
Putting the “Agency” in “Agent”
By definition, implementing an AI Agent means ceding control: Allowing the LLM to determine which tool to call, which data to fetch, and in which order to execute steps. This nondeterminism is inherent to agentic systems, and in direct opposition to how we as 'Product People' have always delivered software... but more on that later…
In delivering AI Agents, start by defining the action boundaries: the data, APIs, database queries, MCPs… all of the individual pieces of context and tooling your Agent needs to achieve the objective. These tools and contexts might be shared across Agents, and the tight scoping increases the likelihood of success. This is exactly how we’ve implemented our Agent fleet at Revcast: small, purpose-built Agents sharing specific subsets of tools and data.
Your Data Pipeline
“Garbage in, garbage out” is both a cliché and, in the case of LLMs and software in general, a ground truth. Clean, normalized data sources, well-defined, business-logic-driven data schemas, and performant processing pipelines are something you control, and principles of good software architecture, just like they’ve always been.
Less is more. Well-defined, thoughtful data schemas are paramount to delivering Agents that actually work instead of getting bogged-down in context pollution and as it turns out, longer prompts have less accuracy than shorter prompts. Bottom line: Provide agents with the minimum-necessary context to do the required task, meaning your production system probably looks a lot like more Agents* with less context.
(*Your CEO will be ecstatic.)
Tool Selection
An Agent without reliable tools is just a chat window. The real power of AI Agents -- as in our above definition -- is their ability to understand natural language in order to discern the right data and tools needed to solve the problem. For existing SaaS products, these tools might (and likely should) utilize existing architecture: APIs and services that already exist to help solve the problems of data retrieval, information processing, and entity CRUD.
Here at Revcast, each of our purpose-built AI Agents has access to a specific subset of the entire box of tools. This affords us better control over the user experience by limiting the full context for each individual Agent to avoid explosion and the degraded user experience of not delivering the desired outcome.
Prompt Iteration
Treat your prompts as living artifacts that will evolve as your product - and the underlying models - evolve. Take a lean, KISS-driven approach in order to find out what really matters rather than drowning in the false promise of the “perfect” system instruction. I’ve seen success engaging internal stakeholders and subject matter experts directly: Give them the prompt, let them experiment with the model, and help them help you teach the Agent how to deliver the objective.
Prompt “engineering” is the most directly-collaborative piece of the puzzle. Whereas stakeholders and SMEs won’t directly commit code for data context or tool calls, they can directly influence the system prompt and instructions through their expertise in a beneficial way.
Context is King
In the world of AI Agents, “context” isn’t just a handful of prompts and parameters, but rather the full curated mix of domain knowledge, user state, and reference data that anchors every decision the Agent makes. Get this wrong, and you and your customers watch as your Agent hallucinates with the confidence of a TED Talk speaker while delivering the utility of a Magic 8-ball. Except in this case, violently shaking the system doesn’t change the outcome.
Context Big Enough is Indistinguishable from Noise
We learned this context lesson, coupled with the lesson above about focus the hard way at Revcast with an early foray of ours into AI Agents. As with many information-driven products, we sought to make it easier for people to query their data with natural language, a seemingly straightforward “chatbot” task. The problem was the literal amount of context (quantity of data) and lack of clarity (lack of AI-ready data definitions), which led to far too many LLM replies in the form of “I’m sorry, I don’t have that information” while people stared frustratingly at the Dashboard saying “but it’s right there.”
Our solution is to think of context in a few different buckets within the confines of our product:
1. Static knowledge
Think product documentation, field definitions, industry benchmarks, and SME best practices. This is the backbone of any good knowledge-based LLM chatbot: ask factual questions, get factual answers. Provided to individual Agents piecemeal based on their purpose, these are used to provide contextual information about the Revcast product, market, and customers in order to keep Agents within the bounds of our defined use case: helping Revenue Leaders make better decisions.
2. User context
Every person uses Revcast with a story - personal preferences, recent interactions, their role within an organization - all relevant to their expectations and experience within our product. Taking this into account allows our Agents to be a touch more human, tailoring responses and output based on the objective and also the person. As a Product Manager, this is a prime example of an old problem to think about in a new way: how to deliver a solution that is bespoke to the person to meet their unique needs, without sacrificing for the full base of customers.
3. Page context
When a person is looking at a page in Revcast, not only is the information on the page important for LLM interaction, but the context of the page is relevant for providing the person with the best possible experience. As an example, if a Sales Manager is viewing the report card for an Account Executive, the context is quite different than if that same person is viewing a Team Dashboard. We use this to our advantage by passing the data and information on the page and also context about the page to our classifier agent - tasked with the simple but critical task of determining the right path in Revcast for a natural-language request (more on our classifier later). This light, additional information has proved effective in properly driving people to the right information at the right time.
4. Org context
Finally - and behind tool calls, services, and APIs - is org context. This is, basically, all of the rest of the information in Revcast for an organization.
More is Not Always Better
These last two are where we’ve seen the biggest likelihood to explode the context: It’s simple and easy to just add more, but unlike Barney Stinson more is not always better.
Back to the example of our “Give me a KPI” Agent, our simplest solution was to change the problem a touch and instead deliver a Custom Dashboard Agent: rather than handle advanced tool queries or force the Agent to handle complex calculations, we empower it to deliver a custom Dashboard link with the requested KPIs, including filtering for Team, Segment, etc. This immediately did two things:
- Improved the quality of responses from the LLM: Less “I can’t do that” and getting the data wrong” and more custom Dashboards with relevant information)
- Checked-off multiple key backlogged feature requests: Custom, shareable dashboard links and natural-language data filtering. Feels good.
Until Next Time…
This is a good point to conclude part 1. Next week in part 2, we’ll dig deeper into both more learnings and specific examples from building Revcast, including our AI Agent architecture and how we arrived at certain decisions.
As always, if you’re interested in our approach to Agents and Revenue Leadership, or if you’d like to see your data in Revcast, schedule a demo. I’d love to show you what we’re building first-hand.


