


In part 1 we introduced our approach to building Genuine AI Agents, including a dive into the definition of a Genuine Agent, and how context and focus play a big role in delivering the optimal product experience. This time, we’ll go even further: by talking about keeping it simple, and looking at specific examples of our Agents and architecture. Onward!
KISS
Nothing lights the fire of smart engineers like new, emergent technology. It's equal parts a learning opportunity and a chance to play with interesting software (plus, as us Product Leaders hope, an opening to drive business value).
Before long, it’s multi-LLM-Agents coordinating via sprawling directed acrylic graphs with enough orchestration to make Kubernetes blush.
Of course the rub, as always, is that every layer of complexity adds another layer of complexity. More points of failure. More potential for latency. More cases to test. More code to maintain. Another ground truth of software engineering. And now in the world of vibe coding AI Agent-assisted software development, these complexity decisions compound in ways even more detrimental to delivering great software: from additional onboarding overhead to context explosion and extra token burn.
Example: Query Classifier
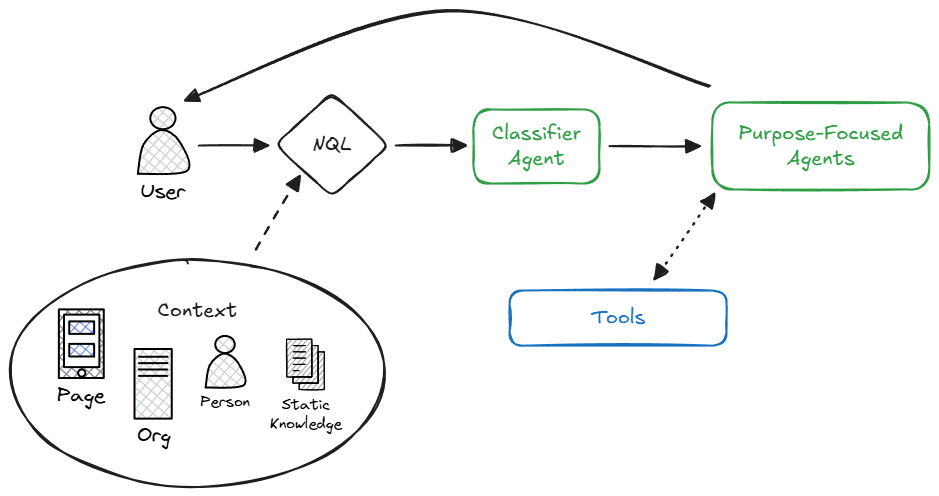
As a real example, let’s talk about the Revcast AI Agent architecture, and more specifically our query classifier. All natural language input from folks using Revcast -- whether from inside the product or via third party tools like Slack -- goes through this classifier, with the intent of identifying the right next step for the user and the system based on the query. Naturally, this Agent is as mission-critical as the text input box used by the humans: if it doesn’t work well, the core value proposition of the Agent is null and void.
The first iteration of our classifier was a basic LLM implementation: a single chat-completions call behind a lean system prompt, fed a small slice of context (the page the user was on, the active filters, and a touch of org metadata) so it could decide the next step without drowning in tokens. Every natural-language user query (from inside the product and from third-party clients like Slack) hit that endpoint, which returned intent and a confidence score, then handed control to the right specialist via our manager/orchestrator layer. It worked: with fewer than five agents in the fleet, it routed cleanly, but latency was perceptible enough to warrant a rethink as usage ramped.
This first delivery proved successful in handling our relatively small (<5 at the time) cadre of Agents. With more usage came more cases where the LLM classifier seemed ripe for optimization. Specifically, the performance was slightly slower than we would have liked -- enough to be perceptible to folks using the product. This, coupled with our adding more Agents, necessitated a revisit: We can do better.
So, inspired by well-thought-out solutions and resources like this, we did what any good Product Team does: Experiment. After investigating potential solutions, a dedicated full-team planning session, and five days of work from a Senior Engineer, we arrived at the same basic approach: A single LLM classifier with a few training examples in the instructions, using a smaller model than before. Faster than our original implementation, and although not quite as fast as more dedicated similarity search models like FAISS, far less code to manage, fewer dependencies, and less need to provide a robust training example set. This success has continued as we’ve added more Agents to our suite, and preliminary tests suggest this classifier implementation will scale to 50+ individual Agents with no trouble. We love it when a plan comes together!
The end result was a system that is more maintainable, with good separation of concerns and single responsibility within the Agent layer, while also improving the experience of customers. Further, current customer usage -- and struggles -- point to the limitations of our Agent system being outside the concerns of the classifier. Sound familiar? Keeping it simple was not only the right solution (even though it may violate our best intentions to do more with emerging and fun technology), but it also helped us focus on what’s most important: The experience of people using Revcast.
Use Agents in conjunction with other software to add value
Just like AI is a small subset of software overall, LLMs are a small subset of AI. The good news is that we can act accordingly, and resist the urge to make the LLM the “product”. Like always, build software that solves the problem. Apply LLMs (and more broadly, AI, but we’ll get there) where it’s necessary, in particular where language is the bottleneck. Right tool, meet the right job.
Use the Right Tools for the Right Jobs
Remember how an AI Agent without tools is just a chat window? The flip is just as important: the value comes from the border where probabilistic language meets deterministic software. While the LLM decides and explains, your core business logic executes and guarantees.
In practice, we keep the roles clean. Broadly, the LLM interprets messy, human requests, picks a capability, and frames the result in human terms. Everything that must be correct, accurate, and mission critical -- think data access, calculations, permissions, error handling -- runs in software and services we already trust (and, for the most part, that we’ve already built). That separation is not a matter of being pedantic: it’s how you get accuracy, quality, and auditability at the same time.
Within the Agent architecture, individual Agents have access to a specific subset of tools through strict schema definitions. Chat inputs are validated, outputs are structured, and every LLM decision and data handoff is traceable: which tool was selected with what parameters and why? If a tool or the Agent fails, there’s no improvisation: The Agent retries, falls back, and asks clarifying questions. Put simply, the model handles judgement, the software handles consequences.
Designed this way, LLMs aren’t our forecasting engine or calculator; they’re the intent router, discernment layer, and explainer. This gives people room to ask squishy, human questions (“What do next-quarter bookings look like if we add two AEs in September?”), letting LLMs do a job they do well: understand intent and assemble tools. Just as critical, this keeps LLMs from doing jobs they are not as adept at, such as arithmetic.
Example: Time-series Data & Sales Ensemble Forecast
Basic addition and subtraction is one thing, and when we get into even more advanced analysis (aka “math”) the struggles of LLMs are compounded. Bottom-line: numerical analysis is not an LLM problem, it’s a data modeling and data quality problem.
Inside Revcast, data analysis is handled by purpose-built algorithms, some of which are ML or AI, some of which are purely deterministic #righttoolfortherightjob. As a practical example, consider this demonstration of our AI-Driven Sales Forecasting feature:
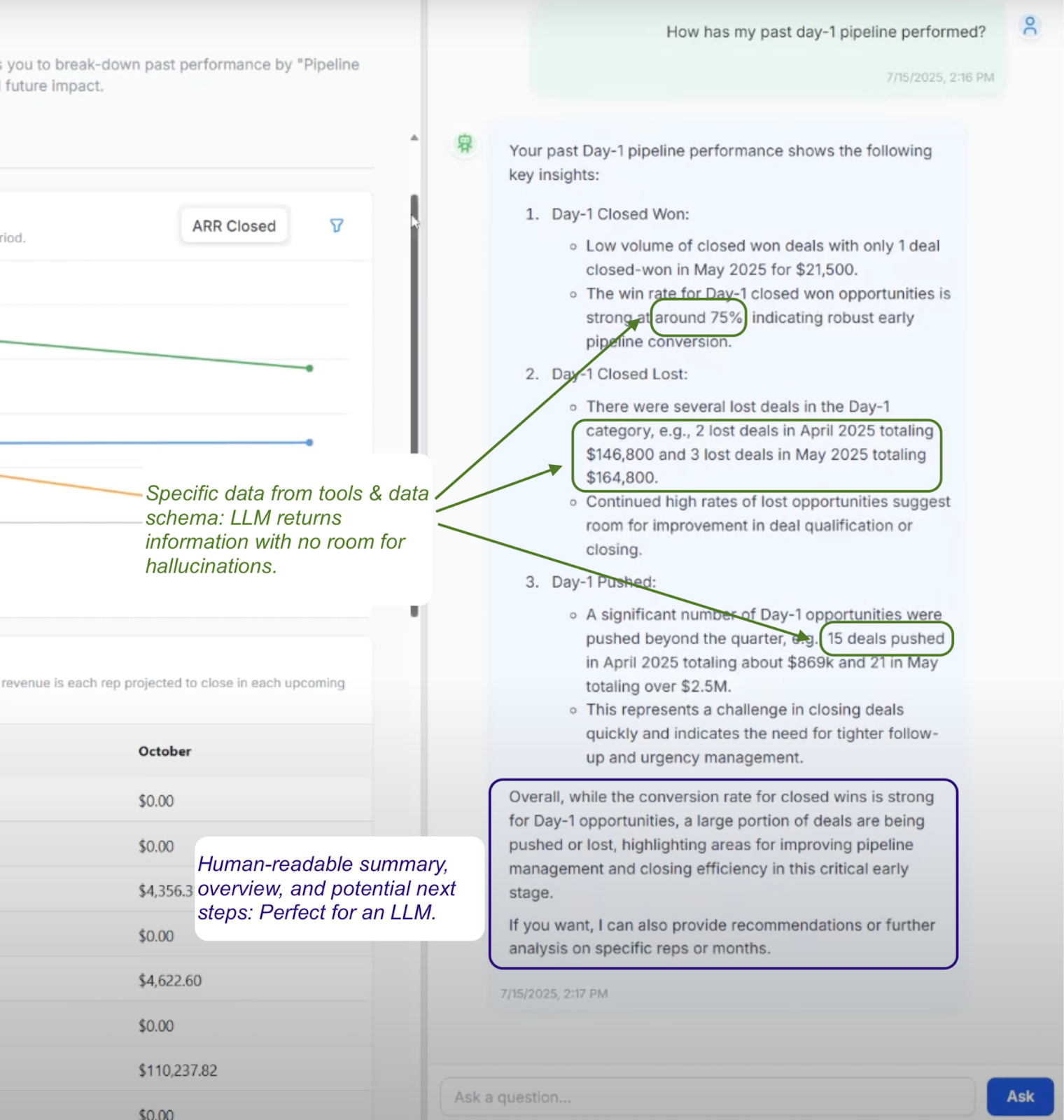
From 3:00: We can see a chat response from our ARR Forecasting Agent to a user inquiry. In this case, the Agent uses the tools and context at its disposal to handle the questions. This way, when specific data and information is needed, it is regurgitated directly from the data schema, not interpreted by the LLM. However, when data summaries and additional human context is helpful to fill in the gaps, this is where the actual LLMs come into play. In this example, our LLMs interpret the input of the user, collate the response, and summarize the information for the user.
Behind the scenes, our dedicated forecasting and time-series algorithms handle the heavy-lifting of data science and actual opportunity forecasting.
These mission-critical computations happen, you guessed it, in software purpose-built to analyze time series data and generate forecasts. Many of these services themselves include machine learning algorithms: systems trained on customer data to learn seasonality and trend, adjust for business-specific variables such as ramp and quotas, and generate calibrated forecast ranges with confidence intervals. That’s all AI, too, just more disciplined, quiet, and behind-the-scenes than your friendly neighborhood chatbot.
Keeping it Consumable for the User Experience
Appropriate Agents from our clan - such as the aforementioned Forecasting Agent - have access to these specific software tools in order to help the human do their job, and do so without the added complexity of LLM hallucination and mathematical inaccuracy. These tools return data in a structured way, ensuring data integrity and accuracy for summarization and usage. As in, only once this data is returned does the LLM do its job: explaining in human-terms (“summarize the output of this forecast in a human-readable fashion for a Sales Manager…”), calling-out assumptions, and proposing next steps.
As mentioned in the previous post, chat interfaces, Agentic workflows, and generative UI by definition force us to cede control over the user experience. Structured data and tool outputs allow us to claw some of that control back: keeping LLMs in-bounds while also setting-up the product to do some real work both inside and outside of the Agent flow: think rendering charts from the supplied data or navigating to relevant Team, Employee, or Sales Opportunity records.
The principle holds throughout: LLMs decide and explain, software services compute and guarantee. That’s how you get credible, accurate numbers and enterprise-grade narrative and logic: A structured, tool-driven system, not throwing things at the OpenAI API.
As always, contact us to see a demo of it all in action!


